Cracking the Interview Code

Huru AI Review 2026: Pricing, Features & Better Alternatives
Updated Jul 9, 2026

Generic Interview Questons 2026
Updated Jul 9, 2026

Spark Hire Interview Questions and Answers 2026
Updated Jul 8, 2026

How to Show Googleyness in Your Interview
Updated Jul 7, 2026

Mastering Codility Interview Questions
Updated Jul 6, 2026
Cluely vs Interview Coder: Honest 2026 Comparison
Updated Jul 5, 2026
LockedIn AI vs Cluely: Honest 2026 Comparison
Updated Jul 5, 2026
Final Round AI vs Cluely: Honest 2026 Comparison
Updated Jul 5, 2026

Job Interview Questions and Answers Sample for Freshers 2026
Updated Jul 5, 2026

Best Undetectable AI Interview Tools for Live Interviews (2026)
Updated Jul 4, 2026

How to Introduce Yourself in an Interview (Best Sample Answers)
Updated Jul 4, 2026
GhostPilot Review (2026): Hands-Free Copilot Tested
Updated Jul 3, 2026
InterviewFox Review (2026): Dual-Device Copilot Tested
Updated Jul 3, 2026
LastRound AI Review (2026): All-in-One Copilot Tested
Updated Jul 3, 2026

Google Interview Warmup Review and Best Alternative
Updated Jul 3, 2026

Final Round AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jul 2, 2026
We Analyzed 12,409 Real Interview Questions: 58% Are Behavioral, Not Technical (2026 Study)
Updated Jul 2, 2026

How to Answer the Job Interview Question “What Are Your Weaknesses?”
Updated Jul 1, 2026

Answering the Top STAR Interview Questions
Updated Jun 30, 2026

How to Answer 50+ Essential Behavioral Interview Questions in 2026
Updated Jun 29, 2026

Top AI Interview Preparation Tools 2026 (Free + Paid)
Updated Jun 27, 2026

How to Follow Up After an Interview in 2026 (Templates)
Updated Jun 22, 2026

CI CD Interview Questions
Updated Jun 18, 2026

Best Questions to Ask at the End of an Interview (2026)
Updated Jun 17, 2026

Next.js Interview Questions & Answers (2026 Guide)
Updated Jun 16, 2026

Integration Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026
What to Say in an Interview if You Have No Experience
Updated Jun 15, 2026

Operating Systems Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Front End Developer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Mastering the STAR Interview Technique: Your Go-To Guide in 2026
Updated Jun 15, 2026

50 Essential AWS Solution Architect Interview Questions & Expert Answers
Updated Jun 15, 2026

Project Manager Interview Questions with Sample Answers (Complete List of 100 Questions)
Updated Jun 15, 2026

The Ultimate List of Google Interview Topics for Tech Roles in 2026
Updated Jun 15, 2026

How Freshers Can Answer the 50 Most Important HR Interview Questions in 2026 (With Examples)
Updated Jun 15, 2026

Vue.js Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Project Manager Interview Questions 2026
Updated Jun 15, 2026

Top Amazon Interview Questions and How to Craft Winning Responses to Land a Job in 2026
Updated Jun 15, 2026

Mastering AWS DevOps Interview Questions in 2026
Updated Jun 15, 2026

How AI Can Help You Prepare for Job Interviews?
Updated Jun 15, 2026

Engineering Manager Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Best AI Tools for Live Interviews and Real-Time Interview Assistance and Coaching
Updated Jun 15, 2026

How to Use Mock Interviews for Effective Interview Preparation in 2025 (Complete Guide)
Updated Jun 15, 2026

How to Answer the Most Asked HR Interview Questions in 2026 (With Sample Responses for Success)
Updated Jun 15, 2026

Software Implementation Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Back End Developer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Test Automation Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Full Stack Developer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

How to Introduce Yourself in a Google Interview (With Sample Answers for 2026)
Updated Jun 15, 2026

Solutions Architect Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Best AI Copilot for Coding and Interview Preparation
Updated Jun 15, 2026
10 Unmistakable Signs You Will Get the Job After Interview
Updated Jun 15, 2026

Best AI Interview Question Generators in 2026
Updated Jun 15, 2026

Mastering the “Tell Me About Your Work Experience” Interview Question
Updated Jun 15, 2026

The Ultimate Guide to SSIS Interview Questions and How to Answer Them
Updated Jun 15, 2026

High-Performance Computing Engineer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

What Are Four Questions You Could Ask A Hiring Manager During An Interview?
Updated Jun 15, 2026

Middleware Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

The Ultimate Guide to Informational Interview Questions in 2026
Updated Jun 15, 2026
Infrastructure Architect Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

UI/UX Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Application Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Alternatives to interviewing.io in 2026
Updated Jun 15, 2026

Cloud Security Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Python Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Embedded Software Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

IT Support Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Game Engine Programmer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026
Cybersecurity Analyst Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Software Quality Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Telecommunications Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Technical Program Manager Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Technical Product Manager Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

The Ultimate Guide to Postman Interview Questions — With STAR-Based Answers
Updated Jun 15, 2026

Angular Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

SDET Test Engineer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Product Manager Interview Questions 2026
Updated Jun 15, 2026

IT Project Manager Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

How to Prepare for a Software Engineer Interview in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Software Engineer Interview Questions 2026
Updated Jun 15, 2026

The Ultimate Guide to SSRS Interview Questions
Updated Jun 15, 2026

The Ultimate Guide to Redux Interview Questions
Updated Jun 15, 2026

Customer Service Interview Questions 2026
Updated Jun 15, 2026

The Ultimate Guide to GCP BigQuery Interview Questions
Updated Jun 15, 2026

Spring Boot Interview Questions & Answers (2026)
Updated Jun 15, 2026

How to Answer the Top Business Analyst Interview Questions in 2025 (With Sample Answers)
Updated Jun 15, 2026
Enterprise Software Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Cybersecurity Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Google Company Interview Questions with Answers in 2026
Updated Jun 15, 2026

Is Google Interview Warmup Worth Using in 2026?
Updated Jun 15, 2026
Network Security Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Engineering Manager Interview Questions 2026
Updated Jun 15, 2026

Top Phone Interview Tips and Questions to Help You Succeed
Updated Jun 15, 2026

Data Engineer Interview Questions 2026
Updated Jun 15, 2026

Technical Consultant Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Cracking The Coding Interview With Interview Sidekick
Updated Jun 15, 2026

Best Free Interview Simulator | Interview Sidekick
Updated Jun 15, 2026

Decoded Customer Service Interview Questions for Freshers
Updated Jun 15, 2026

Best AI Interview Answer Generators in 2026
Updated Jun 15, 2026

Best AI Interview Practice Tools in 2026
Updated Jun 15, 2026

The Ultimate Guide to Informatica Interview Questions
Updated Jun 15, 2026

Mastering Your Amazon SDE Interview Preparation: A Great Guide 2026
Updated Jun 15, 2026

The Ultimate Guide to SAP ABAP Interview Questions
Updated Jun 15, 2026

How to Prepare for a Technical Interview: Tips, Strategies & Sample Questions
Updated Jun 15, 2026

Infrastructure Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

The Ultimate Guide to Phone Screen Interview Questions in 2026
Updated Jun 15, 2026
React Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Blockchain Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Reliability Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Software Development Manager Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Business Analyst Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Applied AI Interview Preparation Free 2026
Updated Jun 15, 2026

Ace Your Salesforce Admin Interview Questions With Best Answers in 2026
Updated Jun 15, 2026

Android App Developer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

The Ultimate Guide to Business Analyst Interview Preparation in 2026
Updated Jun 15, 2026

Mastering Google Coding Interview Questions
Updated Jun 15, 2026

How to Crack A Technical Interview Easily in 2026
Updated Jun 15, 2026

Node.js Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Cryptocurrency Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026
Augmented Reality Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Platform Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Software Architect Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

How to Ace System Design Interviews for Senior Engineers in 2026
Updated Jun 15, 2026

Automation Test Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Embedded Systems Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Systems Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

How to Answer the 10 Most Common FAANG Interview Questions in 2026
Updated Jun 15, 2026

Big Data Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

How to Answer the Most Common Exit Interview Questions in 2026
Updated Jun 15, 2026

DevSecOps Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Virtual Reality Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Artificial Intelligence Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Systems Administrator Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Unique Interview Questions to Ask Employers: Your Secret Weapon for 2026
Updated Jun 15, 2026

Security Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Release Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

DevOps Engineer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Data Scientist Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

How to Make a Great First Impression in Your Job Interview in 2026
Updated Jun 15, 2026

IT Infrastructure Engineer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Network Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Firmware Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Robotics Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026
Computer Vision Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

How to Use AI for Effective Interview Preparation (Benefits, Tips, and 2026 Guide)
Updated Jun 15, 2026

How to Answer the Top AI Interview Questions in 2026 (With Sample Answers and Tips)
Updated Jun 15, 2026

Database Administrator Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Quality Assurance Engineer Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

How to Prepare for a FAANG Software Engineering Job in 2026
Updated Jun 15, 2026

How to Prepare for a Cloud Solutions Architect Interview (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

How to Develop the Top Interview Skills to Get a Job in 2026
Updated Jun 15, 2026

Machine Learning Engineer Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Best AI Interview Assistant Software 2026: 10 Tools Tested
Updated Jun 15, 2026

How to Decline an Interview Politely in 2026 (What to Say + Examples)
Updated Jun 15, 2026

What Is a Group Interview?
Updated Jun 15, 2026

Interviewsby.ai Review 2026
Updated Jun 15, 2026

Interviews Chat Review
Updated Jun 15, 2026

Interview Copilot Review
Updated Jun 15, 2026

Cluely Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

LockedIn AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Best AI Mock Interview Tools in 2026 (Expert Guide for Job Seekers)
Updated Jun 15, 2026
InterviewBee Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026
InterviewHacker AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Affordable AI Interview Software Options That Actually Work in 2026
Updated Jun 15, 2026
Linkjob AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Interview Coder Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Full Stack Developer (MERN) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Penetration Tester (Ethical Hacker) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026
InterviewMan Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Research Engineer (Tech) Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026
Interview Hammer Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

JobLander Review 2026: Free AI Interview Copilot — Honest Verdict
Updated Jun 15, 2026
OphyAI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026
Introducing: Stealth Mode
Updated Jun 15, 2026

Mobile App Developer (iOS) Interview Preparation in 2025 (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Interview Copilot.io Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Best AI Interview Coach in 2026: The Complete Guide
Updated Jun 15, 2026
Continuous Integration (CI) Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Full Stack Developer (MEAN) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

SDET (Software Development Engineer in Test) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Full Stack Developer (LAMP) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026
360Interview AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026
Natively Review 2026: Open-Source Cluely Alternative — Honest Verdict
Updated Jun 15, 2026
Verve AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Site Reliability Engineer (SRE) Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Jun 15, 2026

Live Interview AI Review 2026: Pricing, Features, and Honest Verdict
Updated Jun 15, 2026

Teal InterviewAI Review 2026: Free Mock Interview Tool, Honest Verdict
Updated Jun 15, 2026

Ninjafy AI Review 2026: NinjaCopilot Stealth Coding Tool, Honest Verdict
Updated Jun 15, 2026

Site Engineer (Tech) Interview Preparation (Step-by-Step Guide with Examples)
Updated Jun 15, 2026

Best AI Interview Assistant 2026: 10 Live Copilots Tested
Updated Jun 9, 2026

How do you introduce yourself in an Amazon interview?
Updated Jun 2, 2026

Mastering the Fraud Analyst Interview
Updated May 31, 2026

Best AI for Interview Preparation 2026: 10 Tested (Honest Verdict)
Updated May 21, 2026

Parakeet AI Review 2026: Pricing, Features, and Honest Verdict
Updated May 19, 2026

Sensei Copilot Review 2026: AI Interview Assistant Worth It?
Updated May 5, 2026
Acedit Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026
Sensei AI Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026
MockWin Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026
Beyz AI Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026
CoPrep AI Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026
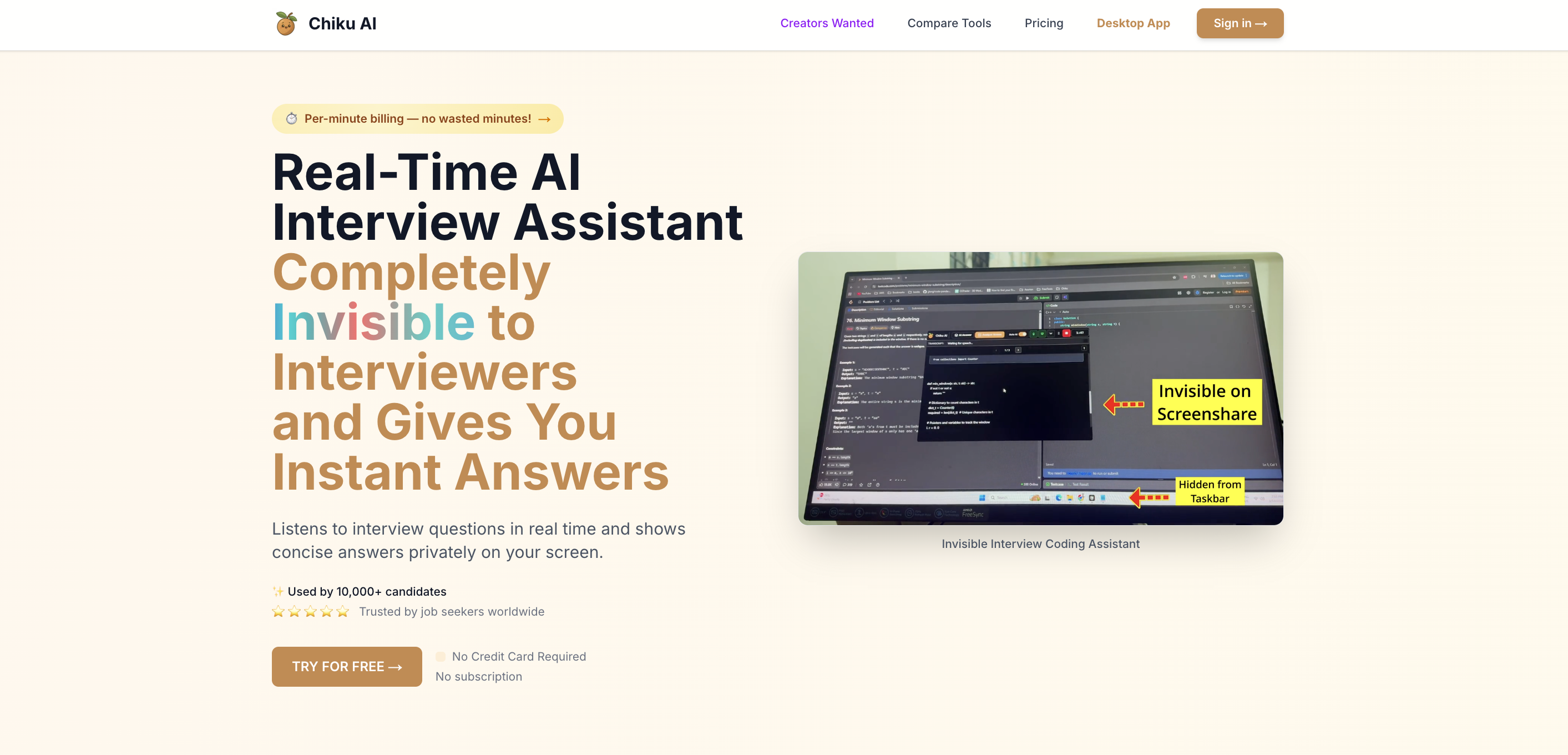
Chiku AI Review 2026: Pricing, Features, and Honest Verdict
Updated May 2, 2026

10 Best AI Interview Assistants in 2026
Updated Apr 25, 2026

Mastering the ‘Tell Me About Yourself’ Interview Question
Updated Feb 18, 2026
![Thank You Email After Interview: 10 Templates That Get Responses [2026]](https://framerusercontent.com/images/agq9HZ6nufqr2kQO4rpvonTVys.png)
Thank You Email After Interview: 10 Templates That Get Responses [2026]
Updated Feb 17, 2026

Anthropic Interviewer Explained: How AI-Led Interviews Work
Updated Feb 17, 2026
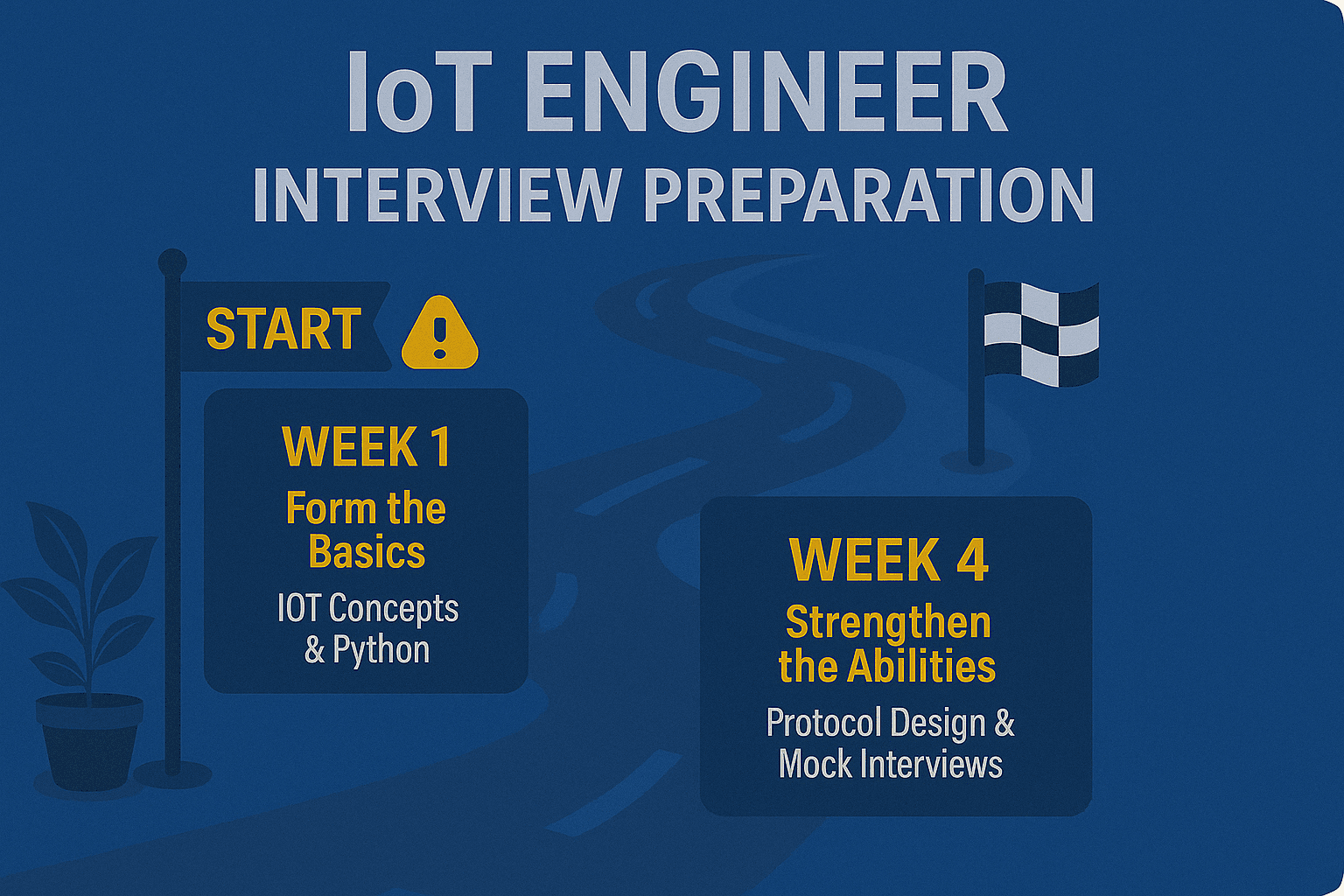
IoT Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

UI Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

10 Best AI Interview Bots in 2026
Updated Feb 17, 2026

C# Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Java Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Game Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Data Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Killer Questions to Ask Employers: Stand Out in Your Next Interview 2026
Updated Feb 17, 2026

Google Interview Questions 2026: Your Ultimate Guide to Success
Updated Feb 17, 2026

RPA Developer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Data Analyst Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

Cloud Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026
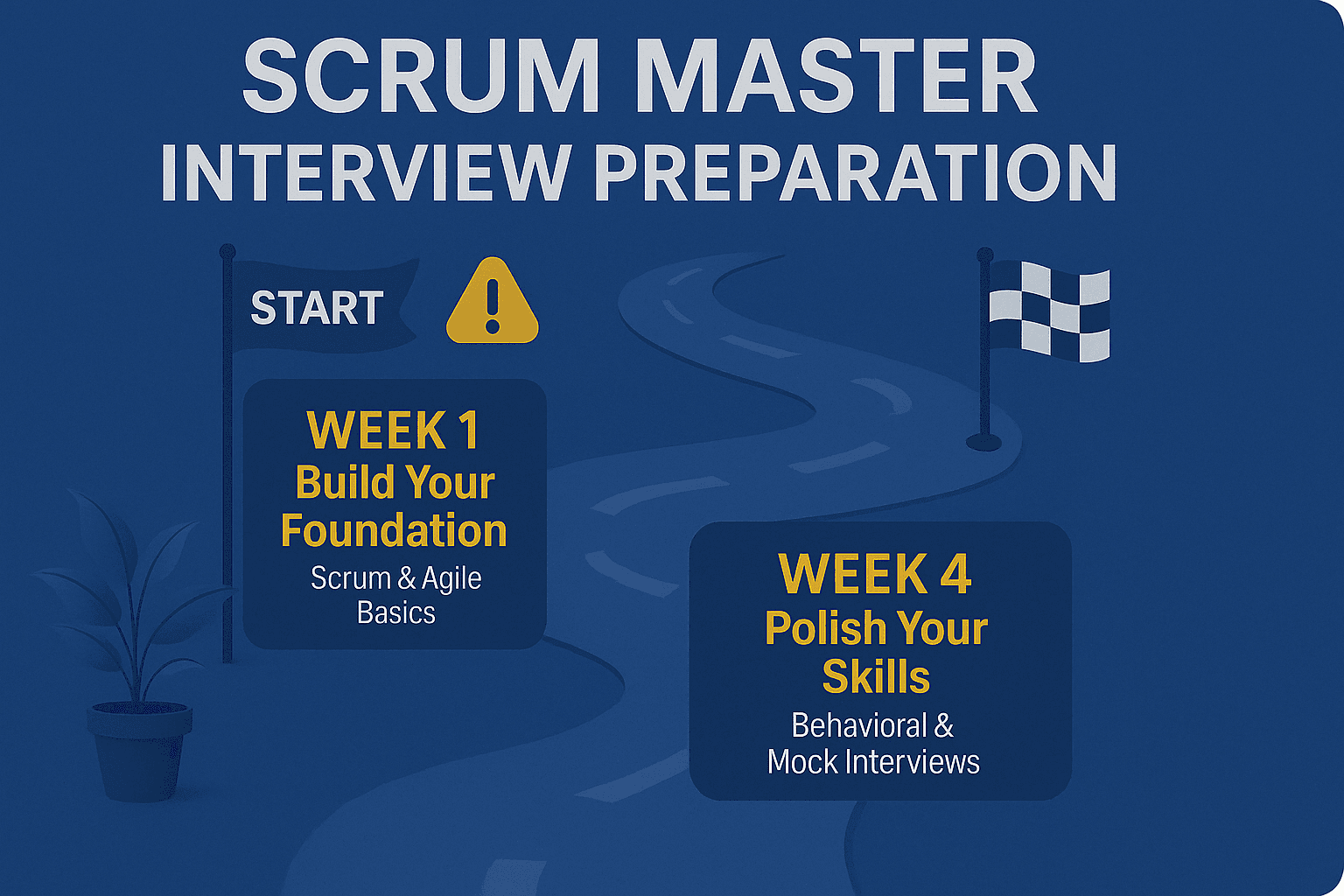
Scrum Master Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026

NLP Engineer Interview Preparation (Step-by-Step Guide with Tips and Examples)
Updated Feb 17, 2026